
Body. Corpus. The material manifestation, the incarnation, even, of the Piers Plowman text in real, fleshy (or pulpy), material objects.
If we think of the corpus of Piers Plowman as inclusive of all its various instantiations and incarnations, how do we think about seeing all of it at once? And moreover, how can we know the specificities of those discrete bodies that contain the poem? What else might be in those same bodies with Piers ? What other limbs, organs, or members might this body have? What becomes visible if we decide to take the entirety of the manuscript corpus as intrinsic to our definition of what the Piers Plowman corpus–its material and textual body–really is?
In an effort to try to see what kinds of texts make up this corporeal phenomenon, I attempted to create a single graphic that displays all of the contents of all of the various Piers Plowman manuscripts and their material relation to one another as well as the frequency of their occurrence in the corpus.
The result of that endeavor is this Data Visualization Network created in R with igraph package.
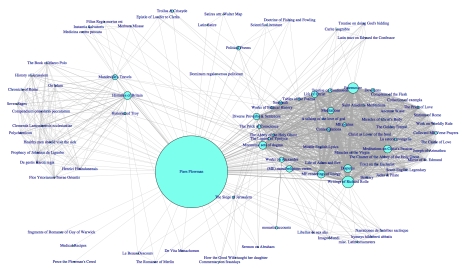
What you are looking at here is a graph of the co-occurrences of works within manuscripts that also contain Piers Plowman. It’s important to note that this graph is oriented around Piers, since that’s what we care about here. This chart will only tell you about these works’ relationship to Piers in Piers MSS and their relationship to each other in Piers MSS.
That said, what you can see here is a visual index of how many different works appear in Piers Plowman manuscripts, and how often those works (or categories of works) reappear. I will take this moment to say that even this attempt to represent the whole corpus is an approximation, with some necessary simplifications.
The meat and potatoes here is first, that each node on the graph represents a work or kind of work in a manuscript that also contains Piers Plowman. The size of the node increases in direct proportion to the number of times the work appears in the corpus. In some cases, I condensed into a single category certain works or kinds of works because what seemed more important to me was to see the commonalities and things that overlap more so than an “exact” representation of the works of the corpus. Thus, the four or five different writings of Richard Rolle don’t each get their own node. Rather, you can see that “Writings of Richard Rolle” occur with a great deal of frequency in the corpus, which seemed more meaningful than knowing that there are two Forms of Living, one Fire of Love (Middle English), and one Latin text of Rolle’s commentaries on Job and the Psalms. This way I can see the general pattern of Rolle’s relative frequency of inclusion rather than measure each work against the other. At another time I may find the other information more meaningful.
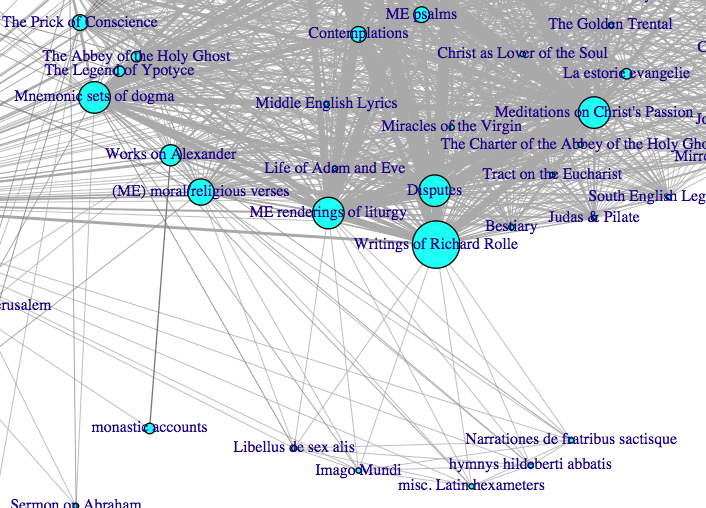
Now, the lines connecting each node–these are called “edges” because they are ‘undirected’ network relationships–indicate any two works’ co-occurrence within the same manuscript. Just as the nodes grow with the increasing incidence of the work they represent, the edges grow with the increasing co-occurrence of two works together. That is, if the line between two nodes is thicker, it means they occur together more often.

When you see a nasty-looking web of interconnections, you are likely looking at a moderate to large sized compilation manuscript. In a compilation, every single node must be connected to every single other node to denote that they all occur together in one material object. The biggest cluster on this graph is actually representative of the Vernon manuscript. Now, with its over 370 different works, the Vernon itself could have completely dominated this graph and drowned out all meaningful information. In order to control for that, I’ve simplified the Vernon by choosing only to list named and known works (like the Ancrene Wisse or the Siege of Jerusalem or the Prick of Conscience) and then to categorize many of the anonymous and uniquely attested works under large categories like “Middle English verse prayers” or “mnemonic sets of dogma” (referring to things like “The Seven Deadly Sins” or “The Seven Works of Mercy”). These condensations are indeed arbitrary, done simply to make visible what I thought was meaningful. There are also likely to be minor errors, in the Vernon contents in particular, since huge portions of the manuscript are under studied. No doubt as the contents of the Vernon get more attention from Scase’s digital facsimile, this graph can grow and change and get more accurate.
The other large cluster on this graph is Cambridge University Library Dd.1.17, a monastic collection of histories and Orientalia, largely in Latin, that sneaks Piers in quite near the back of the manuscript.

Is it a perfect representation? No. Of course not. What it does allow you to do for the first time, though, is to digest hundreds of pages of catalogue information about what’s in the Piers Plowman manuscripts (other than Piers) in a single glance.
Curious about whether Langland and Chaucer circulated together? Once. And a fragment. Troilus and Criseyde in both cases. With Gower? Never. Curious about whether there’s much of the alliterative tradition in these MSS? Some, but not as much as their is of vernacular religion. Come to the corpus with no real driving questions? That’s fine. Did you notice that the single work with which Piers Plowman circulates most often (as opposed to category or author) is The Travels of Sir John Mandeville?
There are any number of new contextual questions that this kind of graphing brings to light. The graph itself is not meant to be an answer to a question, but a new presentation of the best data we (or I) have at any given moment in order to generate new and interesting lines of investigation and interrogation. As the data grows better, as more work is done, the graph grows better.
As always, if you have questions, suggestions, or more information than I do, please share! I’m happy to update my database.

Angela – It’s great to see you using igraph/Gephi for visualizations of MSS and texts. This is a wonderful approach, and your insistence on MSS catalogue data as, properly, data, rather than metadata, is particularly welcome. I’ve long wanted to see these types of info aggregated for mss/texts – particularly as a dynamic diagram, allowing the user to click a node and re-focus directly connected texts/mss.
You’re making some (quite sane) choices about granularity, but you might consider using New IMEV/IMEP numbers for texts and variants, to incorporate yet another set of unique identifiers. Also, in your JSON post the other week, you might use LALME’s LPs, rather than only human-readable forms of dialectal localization. Both involve a lot of work that isn’t necessarily the direction you’re going in with your research, so please take both suggestions as simple enthusiasm. I’m very much enjoying the exciting early stages of your material Piers work – thanks for sharing.
These are some great suggestions on how to integrate data. On tomorrow’s code post I’ll just be talking about adding context for JSON-LD, but as the project moves ahead I might look into both LALME identifiers for dialect and using IMEV/IMEP numbers wherever applicable (which, of course isn’t everywhere given the amount of Latin in this corpus). These are both excellent suggestions, so thanks for these. Be warned, I may tap you for collaboration on implementing them!
What a great project! I hope you’ll consider proposing a panel for Piers2015Seatle on Digital Piers?
I am indeed working out what to propose, though I’m a little stymied by the open call, which I confess is a genre I’ve never submitted to before. Without pre – formed panels it’s hard to figure out what aspect of or argument from my work to pitch!
I know – it’s confusing. IPPS is a little free-form. Just write to Lawrence Warner – maybe you could submit a whole panel?
I don’t think I can handle another panel this year (my Babel, MLA and Kzoo load is rather heavy), but talking to Lawrence about submission is a great idea. Thanks.